A Sinfonia on Messaging:
- The Voice of Business
- The Voice of Architecture
- A RabbitMQ and txAMQP Interlude
Before we play our third voice in this three-part invention, we need to do some finger exercises. In particular, let's take a look at the concepts and tools we'll be using to implement and run our kilt store messaging scenario.
Messaging
The
RabbitMQ FAQ has this to say about messaging:
Unlike databases which manage data at rest, messaging is used to manage data in motion. Use messaging to communicate between and scale applications, within your enterprise, across the web, or in the cloud.
Paraphasing Wikipedia's
entry on AMQP:
The AMQ protocol is for managing the flow of messages across an enterprise's business systems. It is middleware to provide a point of rendezvous between backend systems, such as data stores and services, and front end systems such as end user applications.
AMQP Essentials
AMQP is a protocol for middleware servers ("servers" is used in the most general sense, here... anything that is capable of running a service) -- servers that accept, route, and buffer messages. The
AMQP specification defines messaging server
LEGO blocks that can be combined in various ways and numbers, achieving any manner of messaging goals, whose final forms are as diverse as the combinations of the components.
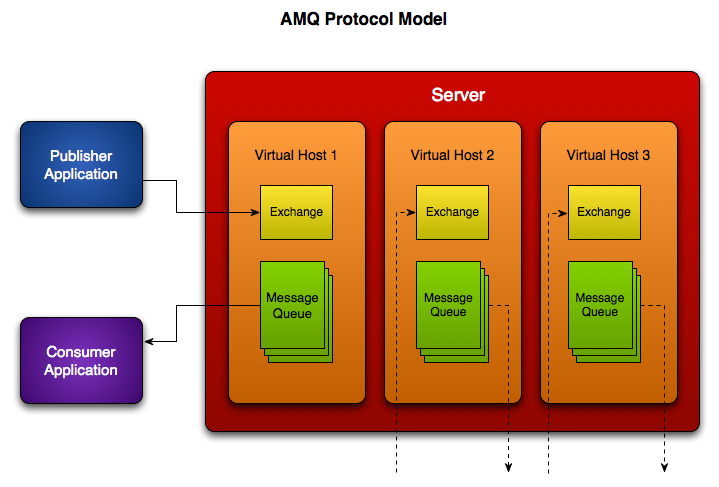
For the visually inclined, below is a simple diagram of the AMQ protocol. I've put multiple virtual hosts ("virtual hosts" in the AMQP sense, not Apache!) in the diagram to indicate support for multiple server "segments" (domains in the most general sense). There could just as easily be multiple exchanges and queues in each virtual host, as well. Likewise for publishers and consumers.
I highly recommend reading
the spec: it is exceedingly clear at both intuitive and practical levels. To better understand the diagram above, be sure to read the definition of terms at the beginning as well as the subsections in 2.1 about the messaging queue and the exhange. Don't miss the message life-cycle section either -- you'll be reminded of circuitry diagrams and electronics kits, which is what AMQP really boils down to :-)
The Advanced Messaging Queing Protocol specifies that the the protocol can be used to create exchanges, message queues, chain them together, and do all of this dynamically. Any piece of code that has access to an API for your AMQP server can connect to it and communicate with other code -- using or creating simple messaging patterns or deeply complex ones. And everything in between.
RabbitMQ Quickstart
RabbitMQ is a messaging system written in
Erlang, but in particular, it is an implementation of AMQP. The RabbitMQ web site provides documentation on
installing and
administering the messaging server. I run mine on Ubuntu, but since I've got a custom Erlang install, I didn't install the package (I dumped the source in
/usr/lib/erlang/lib). To participate in the code play for this blog series, you'll need to install RabbitMQ.
Once you've got it installed, you'll need to start it up. If you've used something like Ubuntu's apt-get to install RabbitMQ, starting it up is as simple as this:
If you've got a custom setup like mine, you might need to do something like this (changing the defaults as needed):
BASE=/usr/lib/erlang/lib/rabbitmq-server-1.5.5/
BIN=$BASE/scripts/rabbitmq-server
RABBITMQ_MNESIA_BASE=$BASE/mnesia \
RABBITMQ_LOG_BASE=/var/log/rabbitmq \
RABBITMQ_NODE_PORT=5672 \
RABBITMQ_NODENAME=rabbit \
$BIN &
A txAMQP Example
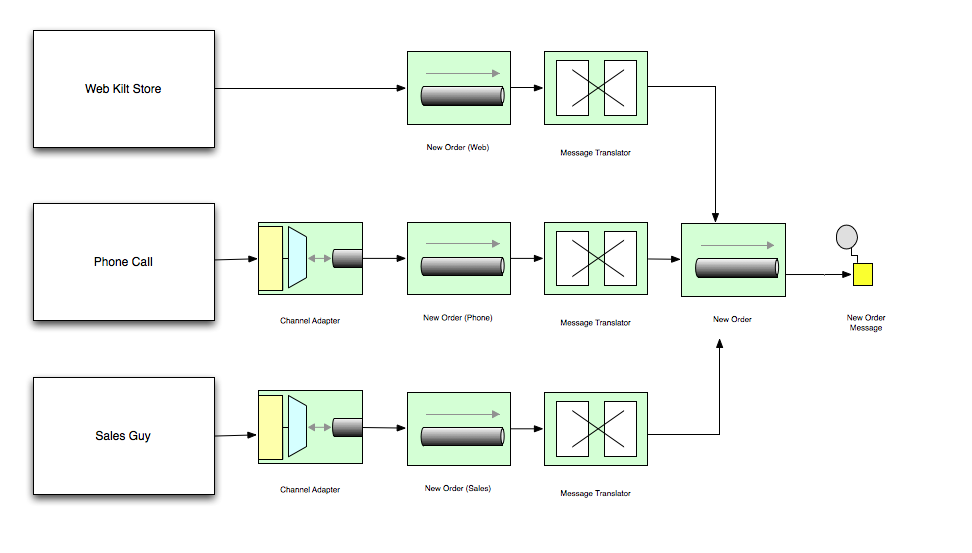
Now that we've got a messaging server running, but before we try to implement out kilt store scenarios, let's take a quick sneak peek at txAMQP with a simple example having the following components:
- a RabbitMQ server
- a txAMQP producer
- a txAMQP consumer
From reading the spec, we have a general sense of what needs to happen in our
producer. It needs to:
- connect to the RabbitMQ server
- open a channel
- send a message down the channel
Similarly, our reading lets us anticipate the needs of the
consumer:
- connect to the RabbitMQ server
- open a channel
- create an exchange and message queue on the RabbitMQ server, binding the two
- check for in-coming messages and consume them
I have refactored some examples that the author of txAMQP
created and I've put them up
here. Once you download the three Python files (and the spec file, one directory level up), you can run them in two separate terminals. In terminal 1, start up the consumer:
python2.5 consumer amqp0-8.xml
In terminal 2, fire off a message:
python2.5 producer amqp0-8.xml \
"producer-to-consumer test message 1"
After running the producer with that message, you should see the same text rendered in the consumer terminal window. You can also fire the message off first, then start up the consumer. The message is sitting in a queue on your RabbitMQ instance and will be available to your consumer as soon as it connects.
Now that you see evidence of this working, you're going to be curious about the code :-) Go ahead and
take a look. There are lots of comments in the code that give hints as to what's going on and the responsibilities that are being addressed.
If you are familiar with Twisted, you may have noted that the code looks a little strange. If you're not, you may have noticed that the code looks normal, with the exception of extensive yield usage and the
inlineCallbacks decorator. Let me give a quick overview:
Ordinarily, Twisted-based libraries and applications use the asynchronous
Twisted deferred idiom. However, there's a little-used bit of syntactic sugar in Twisted (for Python 2.5 and greater) that lets you write async code that looks like regular, synchronous code. This was briefly explored
in a post on another blog last year. The Twisted API docstring for
inlineCallbacks has a
concise example.
Briefly, the difference is as follows. In standard Twisted code, we assign a deferred-producing function's or method's return value to a variable and then call that deferred's methods (e.g.,
addCallback):
def someFunc():
d1 = someAsyncCall()
d1.addCallback(_someCallback)
d2 = anotherAsyncCall()
d2.addCallback(_anotherCallback)
With
inlineCallbacks, you decorate your function (or method) and yield for every deferred-producing call:
@inlineCallbacks
def someFunc():
result1 = yield someAsyncCall()
# work with result; no need for a callback
result2 = yield anotherAsyncCall()
# work with second result; no need for a callback
Visually, this flows as regular Python code. However, know that the
yields prevent the function from blocking (given that there is no blocking code present, e.g., file I/O) and execution resumes as soon as the deferred has a result (which is assigned to the left-hand side). Since this latter idiom is used in txAMQP, I use it in the examples as well.
Next, we finally reach our implementation!
References
 My main development machine is a custom PowerBook running Ubuntu natively. I use it when I'm sitting on the couch, my office comfy chair, the futon, floor, etc. Every once in a while, though, I want to work at a desk from my 24" iMac. Just to mix it up a little. However, that box is my gaming and web-browsing machine: it runs Mac OS X and that's the way I want to keep it. So, if I'm going to do work on the iMac, I need to ssh into the machines that have the environments set up for development.
My main development machine is a custom PowerBook running Ubuntu natively. I use it when I'm sitting on the couch, my office comfy chair, the futon, floor, etc. Every once in a while, though, I want to work at a desk from my 24" iMac. Just to mix it up a little. However, that box is my gaming and web-browsing machine: it runs Mac OS X and that's the way I want to keep it. So, if I'm going to do work on the iMac, I need to ssh into the machines that have the environments set up for development. Now, I just click my "Shells" menu, choose the destination, and start working on that machine. A new window or new tab opened with that instance of Terminal.app will give me a new session to that server, without having to manually ssh into it -- this is even more convenient than having an icon to double-click!
Now, I just click my "Shells" menu, choose the destination, and start working on that machine. A new window or new tab opened with that instance of Terminal.app will give me a new session to that server, without having to manually ssh into it -- this is even more convenient than having an icon to double-click!